
Data Collector Overview and Methodology (version 24)
What are Data Collectors?
Data Collectors are the components of the Canary System that connect to a data source to collect the process data to be transferred to the Canary Historian. Each Data Collector has an interface which allows the administrator to customize how data is logged as well as indicate to which Canary Historian(s) the data is sent.
Types of Data Collectors
OPC UA Collector
- Built to follow the standards of the OPC Foundation for connecting to OPC UA servers.
- Install with Canary Installer. From within the Canary Admin client, users can create, modify, and oversee the status of all OPC UA logging sessions through the OPC Collector tile.
- Configuration settings include the application of deadbands, data transformation, adjusting the update rate (Sample Interval), adding custom metadata, and adjusting the decimal precision of timestamps using timestamp normalization.
OPC DA Collector
- Built to follow the standards of the OPC Foundation for connecting to OPC DA servers.
- Install with Canary Installer. From the Logger Administrator application, users can create, modify, and oversee the status of local and remote OPC DA logging sessions.
- Configuration settings include the application of deadbands, adjusting update rates, configuring pre-defined metadata, creating data transformations, adjusting timestamp decimal precision, and triggering logging based on the value of another tag.
MQTT Collector
- Built to follow the standards of the SparkplugB specification 2.2 and 3.0. In addition to SparkplugB payloads, it can also be configured to consume JSON payloads.
- Install with Canary Installer. From the Canary Admin client users can configure, enable/disable, or monitor multiple sessions using the MQTT Collector tile.
- Configuration settings include the ability to subscribe to multiple brokers and topics, the assignment of primary host to leverage store and forward, using birth and death certificates for state of awareness, as well as enabling TLS security.
SQL Collector
- Supports Microsoft SQL Server, MySQL, and Oracle databases.
- Install with Canary Installer. From within the Canary Admin client, users can create, modify, and oversee the status of all SQL logging sessions using the SQL Collector tile.
- Functionality includes the ability to convert existing historical SQL databases to Canary Historian archives and/or read new ongoing updates. The SQL Collector requires a specific queue table to stage records, imports them at a configurable interval, and then discards the records from the queue table. The performance benefits from this methodology are drastically superior to reading production tables.
Cygnet Collector
- Built to utilize the CygNet .NET API.
- Install with Canary Installer. From the C:\ProgramData\Canary\Logger\StoreAndForward\CygNetCollector folder, edit the SQLite database provided by the Canary team to create or modify CygNet logging sessions. From within the Canary Admin client, users can enable, monitor, or disable existing sessions using the CygNet Collector tile.
- Configuration includes facility and UDC combinations, the mapping of CygNet attributes to Canary tag properties, and the auto-discovery of new CygNet facilities.
CSV Collector
- Created to import flat files using the .CSV format on arrival providing a simple and easy solution for logging data from external systems without using APIs.
- Install with Canary Installer. Requires the modification and creation of two config files: 'SAF_ImportService.config' and 'SAF_Import.config'.
- Very few configurations required, simply determine whether or not you need to archive the CSV file after upload or discard. Flexibility exists in the file formatting, giving you the ability to read CSV files in column-based or row-based data structures.
Canary's Module for Ignition
- Approved by Inductive Automation and available on the Inductive Automation Third-Party Module Showcase.
- From the Ignition Gateway, users can access the 'Config' menu and the 'Modules' submenu to install, configure, and edit the Canary Historian Module.
- Configuration settings include the native historian functionality available from within the Ignition platform, including the ability to log to multiple Canary Historian instances as well as the added flexibility to query data from Canary Historians from Ignition controls.
API Collector
- Offered to allow for custom gRPC or Web API collector development.
- Documentation for the Web API can be found at https://writeapi.canarylabs.com/.
- Configuration settings include the availability of the same calls and settings as used in other Canary Collectors to empower custom collector development.
Data Collector Licensing
The Canary Data Collectors are not licensed and all Collectors are included with the purchase of the Canary System. However, Collectors do need to be installed individually using the Canary Installer. By choosing not to license individual data collectors, it is easier to follow best practice architectures and ensure robust solutions.
Store and Forward (SaF) Service
The Canary SaF service is the main component that works with each Collector ensuring reliable delivery to the Historian. Communication is built on gRPC framework and provides secure and encrypted data transmission. Therein, the SaF service is also responsible for:
- Network/Historian machine state awareness by monitoring the connection between the SaF service on the Collector side and the SaF service on the Historian side.
- Data caching to local disk should the SaF service on the Collector side lose connection to the SaF service on the Historian side. Cache will continue for as long as disk space permits. By default, the SaF service will stop writing new values to disk when only 4000 MB of space remains. (See Store and Forward Tile - Service Settings)
- Notification of system administrators that data logging has not updated in a set period of time (customized by DataSet and managed from the Canary Admin>Historian>Configuration screen).
- Upon the re-establishment of the network or connection to the Historian machine, the SaF service will automatically backfill the Canary Historian archive with all buffered values and clear the local disk cache.
The SaF service is used by all Canary Data Collectors as well as the Historian. Data Collectors communicate with the SaF Service via a public API. This means with some programming knowledge, a user can configure their own custom Data Collectors using the Write API (gRPC or https).
User Authentication
The SaF service supports user authentication through the use of API tokens. API tokens are generated in the Identity service and linked to an internal Canary user who then must be added to the proper access control list within the Identity tile. When it comes to collecting data, API tokens are used
- When logging data from a remote Collector and Tag Security is enabled in the Identity service, and
- When using the Write API for a custom collector
Inserting or Editing Data
The most efficient way to write data is chronologically with the Historian appending the data to the end of the archive. If data arrives out of order, the Historian needs to determine where in the historical archive it should reside which is less performant. In some cases, depending on the data collection method, data is rejected when it reaches the Historian if the timestamp moves in a backwards direction.
If needing to insert or overwrite historical data using the Write API, the user can specify the 'InsertReplaceData' parameter when requesting a session token and set it to True.
When it comes to Canary Collectors, most support data insertions or can be configured to do so. The exception to this is the OPC DA and OPC UA Collectors. If a historical value is received from one of these Collectors an error will be thrown indicating "the timestamp moved in a backwards direction" or "the timestamp is a duplicate" and will be rejected.
Multiplexing Data Streams
The SaF service can send a stream of data to multiple destinations in the scenario where there is more than one Historian within the system architecture. This is typically configured within the Collector by adding additional Historian (or proxy) destinations separated by a comma.
(e.g., HistorianOne, HistorianTwo)
Logging Architecture Options and Best Practices
The Canary System is comprised of components that are pre-integrated to assist in the collection, storage, and reporting of data.

In its simplest form, the Canary System can be broken down into the following components: Data Collectors, SaF's, Canary Historian, and Views.
The Canary Data Collectors and SaF service work in tandem to log data from the data source and push that data to another SaF service that is paired with a Historian. Each Collector/SaF can be configured to push data to multiple destinations. If the connection between two SaF services is interrupted, the SaF service on the sending side will buffer data locally until the connection is reestablished.
The Views serves as the gatekeeper for client data queries, retrieving necessary data from the Canary Historian, performing any aggregated data requests, and then publishing that data to the client, whether it be a Canary client (Axiom, Excel Add-in, Calcs & Events, etc.) or third-party client using Canary's Read API or ODBC Connector.
Most components can be installed individually and provide for flexible system architectures. However, a series of best practices is recommended to follow whenever possible.
Data Logging
Whenever possible, keep the Canary Data Collector/SaF components local to the data source.

Install both the appropriate Data Collector as well as the Canary SaF on the same machine as the OPC server, MQTT broker, SCADA server, or other data collection source.
The benefits of this architecture are based on the SaF's ability to buffer data to local disk should connection to the SaF service on the Historian side be unavailable. This protects from data loss during network outages as well as Historian server and system patches.
When remote from the Historian, data is sent over a single gRPC endpoint (55291) from one SaF service to another.
Should the value of the organization's data not be as important, the Data Collector/SaF could be installed remote from the data source on an independent machine or on the same server as the Canary Historian itself. This form of 'remote' data collection will still work without issue except in the event of a network outage or other cause of unavailability of the Historian. The option of buffering data will be unavailable.
Logging from Multiple Data Sources
Data from multiple data sources can be sent to the same Canary Historian. To accomplish this, create unique Data Collector/SaF pairings as local to each data source as possible. The type of data source can vary (OPC DA or UA, MQTT, SQL, CSV, etc) but the architecture will stay the same.

Redundant Logging Sessions (OPC DA/UA only)
The SaF services moderates which data is logged to the Canary Historian using the tag name, timestamp, value, and quality. In doing so, it monitors each individual tag, only allowing a single unique value and quality per timestamp.
This feature provides simplistic redundant logging as the SaF follows a first-in-wins methodology. Simply put, redundantly logging the same information from multiple sources will result in the SaF service keeping the first entry while discarding any and all duplicate entries. This methodology is only useful when using the OPC DA or UA Collector as neither supports the insertion of duplicate or historical timestamps. If using another data collection method where inserts are allowed, the Historian would end up logging the same timestamp twice from each source. This would be problematic and is not recommended.
Currently, Canary supports a hot/hot environment where both Collectors are actively logging data from their respective OPC server as seen in the image below. This type of architecture supports the first-in-wins methodology. If one Collector/OPC server goes down, the other picks up where the other left off. Canary does NOT support a hot/cold OPC server environment with one Collector for the hot OPC server and one Collector for the cold OPC server. In this configuration data loss can occur when switching which OPC server is hot if there is any buffered SaF data.
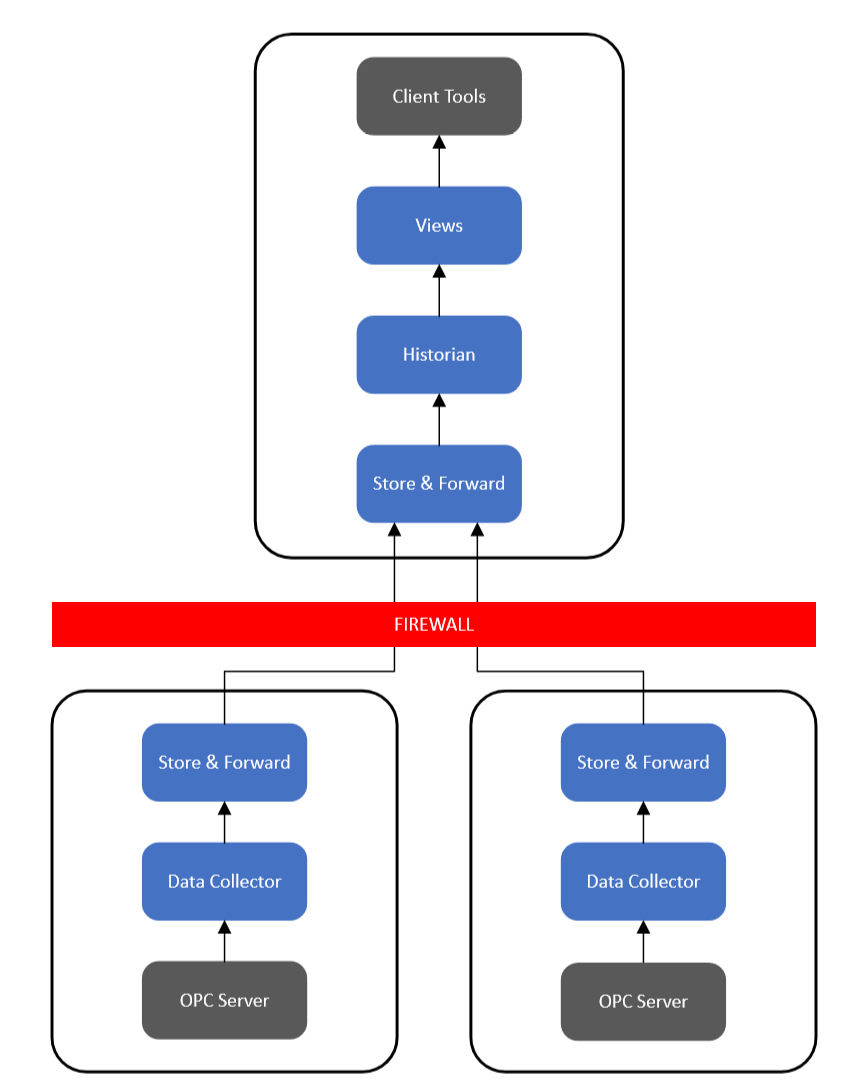
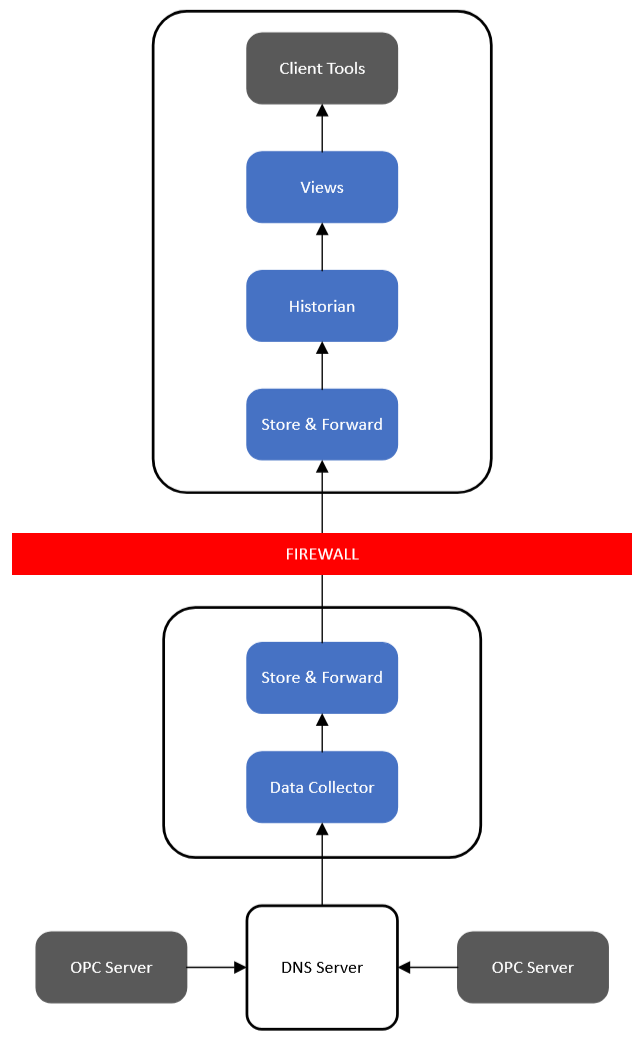
Alternatively, if only wishing to use one Collector, the user can determine which OPC server to connect to through DNS routing. This configuration takes place outside of Canary's software.
Logging to Redundant Canary Historians
Each SaF service has the ability to push data in real-time to multiple destinations enabling redundancy. This is configured within the Data Collector with the configuration slightly varying depending on the collector type. In general, this is accomplished by listing multiple Historians in the 'Historian' field, separated with a comma.
For example, the SaF service would send a data stream across the network to the SaF service installed on the server named 'HistorianPrimary' while also simultaneously sending an identical stream to the server named 'HistorianRedundant'.

This dual logging approach is recommended when redundant historical records are desired and insures that a real-time record is provided to both Historian instances. Multiple data sources can be used as demonstrated in previous architectures. Each data source would need to have the Data Collector configured to push data to all desired Canary Historian instances.
A Canary Historian instance operates independently of other Canary Historian instances. This isolation ensures that the records of each Historian are secure and not vulnerable to data syncs that may create duplication of bad data.
Proxy Servers and Logging Across DMZs
A Canary Proxy Server may also be implemented in logging architectures. This feature provides a standalone SaF service, and would be installed to serve as a 'data stream repeater', often useful in DMZ or strict unidirectional data flows.

Sitting between two firewalls, the Proxy Server manages the incoming data stream from the remote Data Collector/SaF server(s). The Proxy Server then relays the data stream to another SaF service, in this case a level above the Proxy Server and through an additional firewall. Like all SaF configurations, this only requires a single open firewall port for all data transfer and ensures no 'top-down' communication can occur.
Logging to Cloud Historian Instances
Data logging can easily be accomplished to 'cloud' or 'hosted' Canary Historian instances. Again, this is accomplished by simply configuring the Data Collector to include the IP address and security configurations necessary to reach the remote Historian.

Should a local Historian also need to be added to the architecture, an additional Historian instance can be added to the Data Collector configuration and you will begin pushing data in real time to both a local Canary Historian as well as the cloud installation.