
Understanding Canary System Architecture Options (version 24)
The Flow of Data in the Canary System
While not completely exhaustive, the information and architectures below will provide an understanding of deploying best practices and recommendations for the Canary System. Suggested architectures are often flexible and can be adapted to most corporate IT standards.
As you can see from the chart below, many modules work together to complete the Canary System. Shown in blue, each module is integrated to move data to another module or set of modules in order to help you log, store, contextualize, and distribute process data.
Note, the Canary System and the modules that make up the Canary System are usually spread across several servers, whether physical or virtual. These more detailed architectures will be addressed further within the document.

Although overwhelming at first, we can simplify this system be grouping modules based on their typical functionality.
Applying Canary to the Purdue OT Model
As outlined in the diagram below, Canary System components can be installed in a manner that complies with Purdue OT and ISA 95 best practices. Canary components are depicted in blue, however connectivity between components is not accurately represented for simplicity's sake. Some Canary components (such as Publisher and ODBC Server) are not represented but could be added to either Level 3 or 4 as necessary.

Logging Data to the Canary Historian
The Canary Data Collectors and Store and Forward (SaF) service work in tandem to log data from the data source and push it to its destination where it will be received by another SaF service. Each Collector/SaF can be configured to push data to multiple destinations. The SaF service has the ability to buffer data to disk in the event it loses connection with the SaF service on the receiving end.
A SaF service is always installed local to the Canary Historian and writes received values into the archive.
For the time being, we will ignore most modules and Canary components that fall outside of collecting and storing data. We will continue to represent 'Views' which serves as a gatekeeper between 'Client Tools' and the historian archive.
Data Logging
Whenever possible, keep the Canary Data Collector and SaF components local to the data source.

Install both the appropriate Data Collector as well as the SaF service on the same machine as the OPC server, MQTT broker, SCADA server, or other data collection source.
The benefits of this architecture are based on the SaF's ability to buffer data to local disk should connection to the SaF on the Historian side be unavailable. This protects from data loss during both network outages as well as Historian server patches and upgrades.
Should the value of the organization's data not be as important, the Data Collector could be installed remote from the data source on an independent machine or on the same server as the Historian itself. This form of 'remote' data collection will still work without issue except in the event of a network outage or other cause of unavailability of the Historian. The option of buffering data will be unavailable.
Logging from Multiple Data Sources
Data from multiple sources can be sent to the same Canary Historian. To accomplish this create unique Data Collectors as local to each source as possible. The type of data source can vary (OPC DA or UA, MQTT, SQL, CSV, etc) but the architecture will stay the same.

Redundant Logging Sessions (OPC DA/UA only)
The SaF services moderates which data is logged to the Canary Historian using the tag name, timestamp, value, and quality. In doing so, it monitors each individual tag, only allowing a single unique value and quality per timestamp.
This feature provides simplistic redundant logging as the SaF follows a first-in-wins methodology. Simply put, redundantly logging the same information from multiple sources will result in the SaF service keeping the first entry while discarding any and all duplicate entries. This methodology is only useful when using the OPC DA or UA Collector as neither supports the insertion of duplicate or historical timestamps. If using another data collection method where inserts are allowed, the Historian would end up logging the same timestamp twice from each source. This would be problematic and is not recommended.
Currently, Canary supports a hot/hot environment where both Collectors are actively logging data from their respective OPC server as seen in the image below. This type of architecture supports the first-in-wins methodology. If one Collector/OPC server goes down, the other picks up where the other left off. Canary does NOT support a hot/cold OPC server environment with one Collector for the hot OPC server and one Collector for the cold OPC server. In this configuration data loss can occur when switching which OPC server is hot if there is any buffered SaF data.
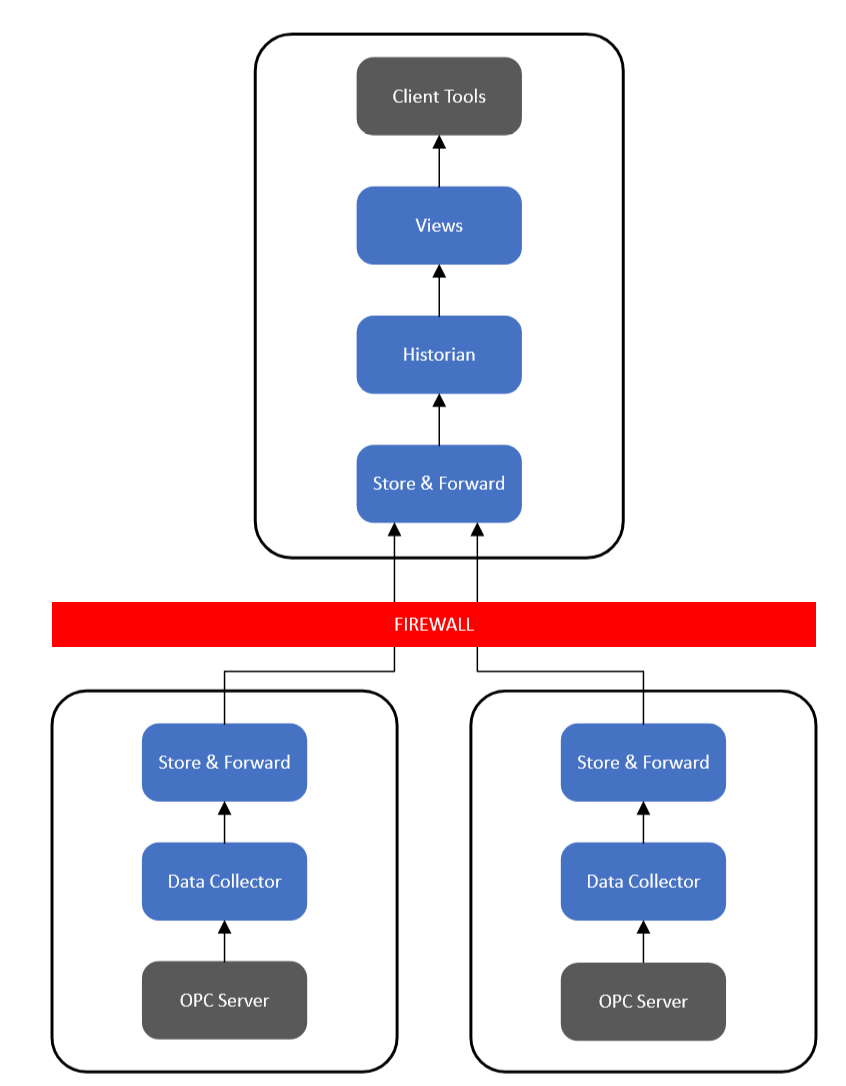
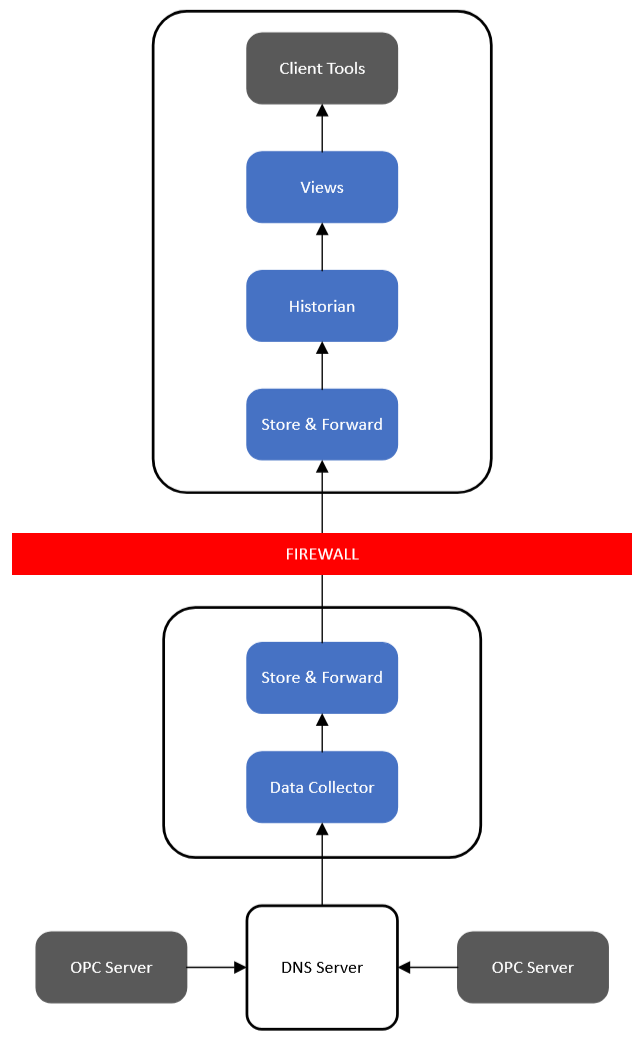
Alternatively, if only wishing to use one Collector, the user can determine which OPC server to connect to through DNS routing. This configuration takes place outside of Canary's software.
Logging to Redundant Canary Historians
Each SaF service has the ability to push data in real-time to multiple destinations enabling redundancy. This is configured within the Data Collector itself. In general, this is accomplished by listing multiple Historians in the 'Historian' field, separated with a comma.
For example, the SaF service would send a data stream across the network to the SaF service installed on the server named 'HistorianPrimary' while also simultaneously sending an identical stream to the server named 'HistorianRedundant'.

This dual logging approach is recommended when redundant historical records are desired and insures that a real-time record is provided to both Historian instances. Multiple data sources can be used as demonstrated in previous architectures. Each data source would need to have the Data Collector configured to push data to all desired Canary Historian instances.
A Canary Historian instance operates independently of other Canary Historian instances.
Proxy Servers and Logging Across DMZs
A Canary Proxy Server may also be implemented in logging architectures. This feature provides a standalone SaF service, and would be installed to serve as a 'data stream repeater', often useful in DMZ or strict unidirectional data flows.

Sitting between two firewalls, the Proxy Server manages the incoming data stream from the remote Data Collector/SaF server(s). The Proxy Server then relays the data stream to another SaF service, in this case a level above the Proxy Server and through an additional firewall. Like all SaF configurations, this only requires a single open firewall port for all data transfer and ensures no 'top-down' communication can occur.
Data Contextualization within the Canary System
Several components interact with the Canary Historian to provide additional data context. These include Views and Calcs & Events.

Views serves as the gate keeper between clients and the Historian. It retrieves and processes the data from the Historian, whether it be raw or aggregated, based upon the request and returns it to the client. As such, additional representations of the historical data, which we call Virtual Views, can be constructed using the Views service. Virtual Views allow for the application of data structure changes, tag aliasing, and asset modeling on top of the Canary Historian without altering the historical archive. When clients request data from the Views, they can browse not only the Canary Historian as it is archived, but additional Virtual Views as well.
The Calc & Events service connects to the Canary Historian through the Views service. Data that is produced within the Calculation service is written back to the Canary Historian via the SaF service. The Calculation service can also create Events which, by default, are stored in a local SQLite database. This Event data is also available to clients through the Views service.
Additionally, the Views service can be used to stitch together multiple Canary Historians and/or multiple Virtual Views so that a client may browse one volume even though it may be spread across multiple servers. This feature allows for unlimited scalability for large systems with millions of tags.

Client Load Balancing
Systems that have large client interaction, typically more than 50 concurrent clients, may consider load balancing the Canary System by creating two separate Views options, one dedicated for Axiom clients, the other for APIs and 3rd-party applications.

This architecture is preferred when APIs are used to connect to the Canary System as it isolates those calls from Axiom and Excel Add-in client activity. This best practice prevents system slow down for Canary client tools should 3rd party applications draw too many resources.
Cloud Architectures

Canary System components may be installed in cloud solutions. These installations should have Canary Data Collectors local to the data source and have the flexibility of using Canary and third party client tools as needed. Additional Canary components may be installed in the Cloud (Calc & Events, Publisher, etc) although they are not represented in the above drawing for simplicity's sake.