
Intermittent gRPC Ingestion Failures Between Store & Forward and Historian
We are experiencing intermittent issues between two Store & Forward (S&F) nodes and our Canary Historian. The S&F services intermittently fail to start or maintain their gRPC connections to the Historian, showing errors such as: “Error starting gRPC call”, “Failed to connect to endpoint”, “StatusCode=Unavailable”, “Target machine actively refused it”.
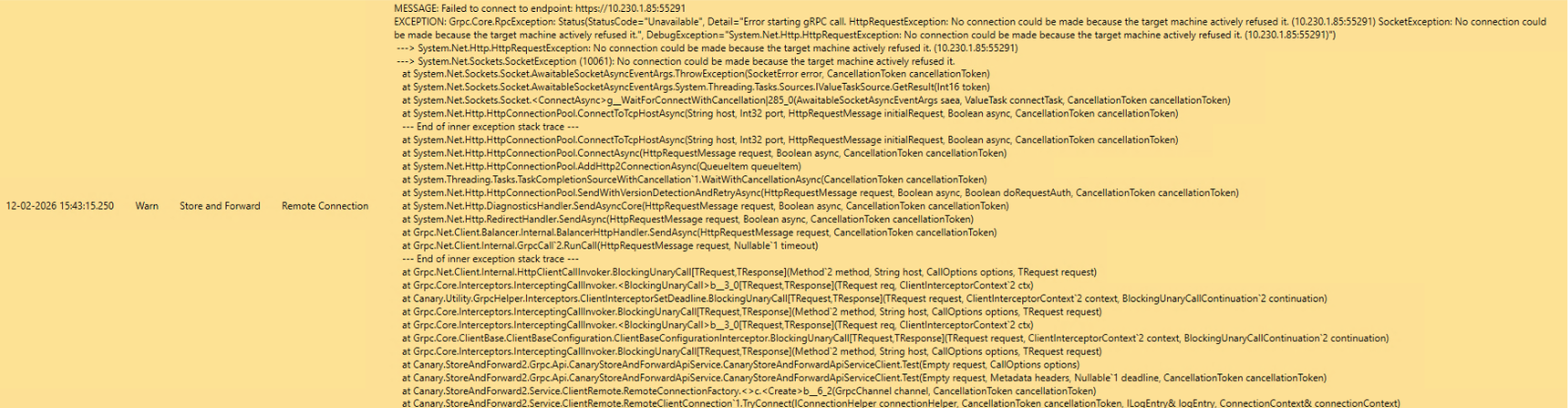
A TCP connectivity test to the Historian port succeeds consistently, so it appears the issue is not network‑ or firewall‑related. However, when the errors occur, both S&F nodes stop sending data temporarily. Once connectivity recovers, we observe a burst of traffic as the backlog is flushed.
We also have traffic graphs that clearly show this pattern:
periods of normal throughput → complete drop to zero → recovery with high bursts.
This behavior repeats across both S&F nodes.
Given this, we are trying to understand:
What conditions in the Canary Historian could cause gRPC streams to fail intermittently while TCP remains reachable?
Could this be related to ingestion engine saturation, internal queue limits, HTTP/2 stream limits, throttling, or service restarts?
Are there recommended metrics, logs, or components within Canary that we should check to diagnose this?
Is there any tuning or best‑practice configuration for S&F → Historian gRPC stability under load?
Any guidance on possible root causes or troubleshooting steps would be greatly appreciated.
Thank you!